Packages and Analytical Tools
Math-Llama-2-QLoRA: is a pretrained large language model based on LLaMA-2 with 8 Nvidia A100-80G GPUs using 3,000,000 groups of conversations in the context of mathematics by students and facilitators on Algebra Nation (https://www.mathnation.com/). Llama-2-Qlora consists of 32 layers and over 7 billion parameters, consuming up to 13.5 gigabytes of disk space. Researchers can experiment with and finetune the model to help construct math conversational AI that can effectively respond generation in a mathematical context.
Math-Llama_Lora: is a pretrained LLM extending from LLaMA with 8 Nvidia A100-80G GPUs using 3,000,000 groups of conversations in the context of mathematics by students and facilitators on Algebra Nation (https://www.mathnation.com/). Llama-mt-lora consists of 32 layers and over 7 billion parameters, consuming up to 13.5 gigabytes of disk space. Researchers can experiment with and finetune the model to help construct math conversational AI that can effectively respond generation in a mathematical context.

Math-GPT-J: is a pretrained GPT-J-6B model (GPT-J 6B is a large language model trained using Ben Wang's Mesh Transformer JAX) trained with 8 Nvidia A-100 GPUs using 3,000,000 math discussion posts by students and facilitators on Algebra Nation (https://www.mathnation.com/). Math-GPT-J uses Rotary Position Embeddings, which has been found to be a superior method of injecting positional information into transformers. It has 28 layers, and 6 billion parameters and its published model weights take up to 24 gigabytes of disk space. It can potentially provide a good base performance on NLP related tasks (e.g., text classification, semantic search, Q&A) in similar math learning environments.
Knowledge-Graph for RAG: This repository contains code for building retrieval-augmented generation (RAG) systems using LLMs such as GPT-4 and Llama 3. The RAG techniques employed include vector-based context retrieval, tree-based, and graph-based (our in-house approach) methods. Additionally, this repository includes code for a semantic classifier utilizing various techniques. It also contains a web application using the knowledge-graph based context retrieval technique.

Prob-Gen-Llama: has two versions of LLMs, a 8B and a 70B Llama-3, fine-tuned using 4-bit QLORA. In collaboration with the Duke NLP lab, we utilized 3,644 GPT-4-generated grade school math word problems vetted by three content experts with PhD degrees in mathematics education. It generates math word problems with contrasting cases, a powerful learning sciences theory evidenced to be effective for math learning, within specified contexts.
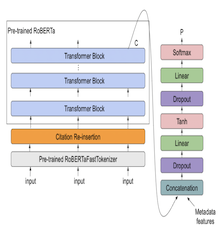
MathRoBERTa cyberinfrastructure: a large language model, which has been trained with 8 Nvidia GPUs and over 3,000,000 math discussion posts by students and facilitators on Algebra Nation. MathRoBERTa has 24 layers, and 355 million parameters and its published model weights take up to 1.5 gigabytes of disk space. Researchers can easily download and utilize this model to conduct a series of natural language processing tasks (e.g., text classification, semantic search, Q&A) in similar math learning environments.

Git_20 Model: is a fine-tuned multimodal visual language model from Microsoft GIT using 1 Nvidia A100-80G GPU. We extracted 100,000 student assignments containing teacher feedback from 3 million student assignments as training data. The training data is divided into the image part of student assignments and the text part of teacher feedback. git_20 consists of 18 layers and over 170 million parameters, consuming up to 0.7 gigabytes of disk space. The project aims to use multi-modal and multi-task deep learning models to create a machine learning pipeline that provides automatic diagnostic feedback for students' mathematical reasoning. Researchers can experiment with and finetune the model to help construct multimodel that can effectively provide automatic diagnostic feedback for students' mathematical reasoning.
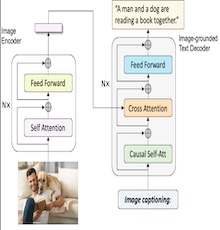
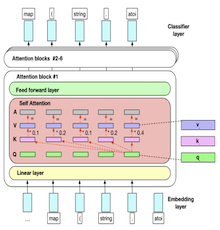
SafeMathBot cyberinfrastructure: build a large language model using state-of-the-art language GPT-2-xlarge which has been trained with 8 Nvidia GPUs and enhanced with conversation safety policies (e.g., threat, profanity, identity attack) using 3,000,000 math discussion posts by students and facilitators on Algebra Nation. SafeMathBot consists of 48 layers and over 1.5 billion parameters, consuming up to 6 gigabytes of disk space. Researchers can experiment with and finetune the model to help construct math conversational AI that can effectively avoid unsafe response generation.
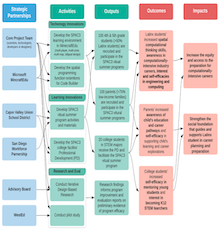
SPAC3: takes an innovative approach to address these gaps and provide evidence-based insights. It aims to develop visual programming functions suitable for upper elementary students, helping them learn spatial programming effectively. By doing so, it will contribute to our understanding of how this tool impacts students' spatial reasoning, computational thinking, and their interest in computationally-intensive careers.